

Broken internal links after a cloud migration are one of the fastest ways to turn a successful technical project into a productivity crisis. When users click links inside intranet pages, documents or dashboards and land on 404s or “access denied,” daily workflows stall, support tickets spike, and trust in the migration plummets.
This guide explains the root causes of broken internal links during a cloud migration, gives a practical pre-migration checklist, outlines step-by-step fixes you can run after the cutover, and shows how to monitor and prevent regressions so your people can get work done.
A single broken page isn’t just an inconvenience, it can cascade across the organization.
Consider an HR help desk article that includes ten links to forms and three links to templates. If even half of those links fail after migration, every employee who relies on that page now has to email colleagues, log a ticket, or improvise.
Multiply that across departments, and what started as a single missing redirect becomes hours of wasted time, missed deadlines, and frustrated staff.
The real cost isn’t just technical - it’s cultural. Trust in the new platform dips. Teams hesitate to adopt other cloud features. And IT finds itself stuck in reactive mode instead of moving forward on innovation.
That’s why broken links aren’t a “post-launch nice-to-have.” They’re a direct threat to adoption, productivity, and the perception of your cloud strategy.
Broken links typically fall into four main categories. Knowing these causes upfront helps you design the right defenses:
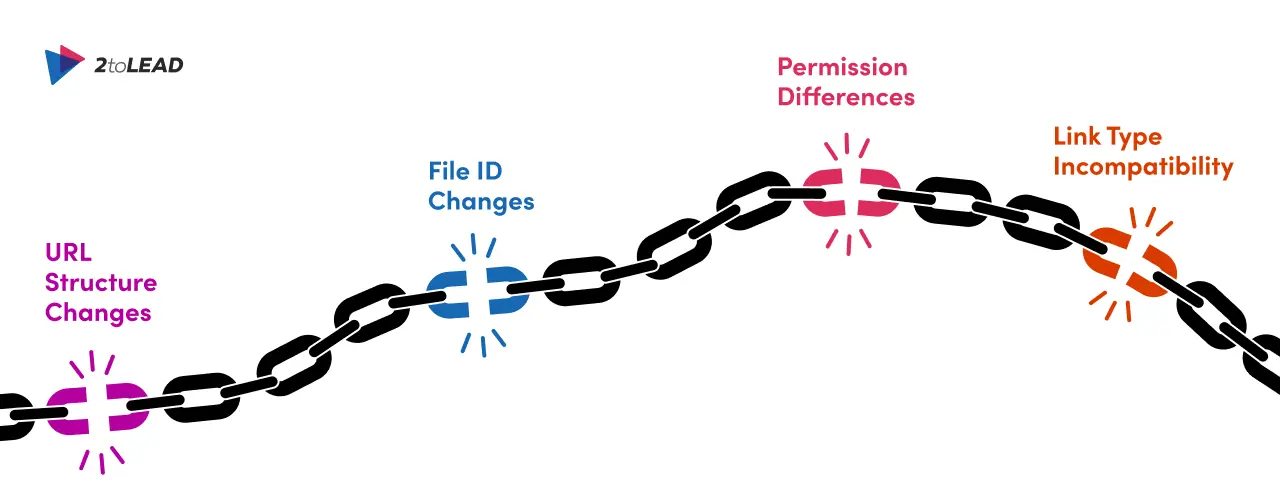
On-premises intranets often have nested folder paths or legacy page naming conventions that don’t map one-to-one into modern cloud site structures. If pages are reorganized, any hard-coded absolute URLs pointing to old paths will become dead links.
Some platforms use internal identifiers (GUIDs) for documents or pages rather than friendly URLs. Migration tooling may create new IDs during transfer, and links that referenced the original ID will no longer resolve.
A broken link can look identical to a permissions problem. After migration, group memberships, Azure AD mappings, or external sharing settings may change; the link exists but users get “forbidden” instead of content, which is effectively a broken workflow.
Links embedded inside Office documents, PDFs, or legacy scripts (e.g., intranet web parts that rely on server paths, mapped drives, or HTTP to file-system links) often don’t translate automatically. Also, links that were relative in one environment may behave differently in the cloud.
For each of these causes, the right preventive step and a targeted remediation dramatically reduce impact.
Plan to detect and preserve links before you move any content. The checklist below is practical. Run it early and treat the outputs as migration artifacts.
The best way to fix broken links is to stop them from breaking in the first place. Here’s a checklist you can run before migration to minimize disruption:
/sites/HRPortal → /sites/HR) and create a redirect plan. These outputs should be treated as migration artifacts. They’re as important as content mappings or cutover runbooks.
Even with planning, some link breakage is likely. Use this triage-to-remediate flow immediately after the migration cutover.
Crawl the migrated environment using the same credentials and roles as typical users. Export a broken-link report that includes HTTP status codes (404 vs 403), source context, and a priority score (e.g., traffic or business impact).
Don’t try to fix everything at once. Prioritize:
Create a triage list of P1 (fix immediately), P2 (fix within 1 week), P3 (monitor).
Some links embedded in legacy file formats or third-party apps will need human review. Triage these into owner-assigned tickets with clear reproduction steps and suggested target URLs.
If primary navigation or global headers contain broken links, fix them first as these affect the most users.
After fixing, re-run the authenticated crawls against the same account set to validate that P1 items are resolved. Track this as part of your migration acceptance criteria.
You don’t need to buy every product to succeed. Combine the right capabilities.
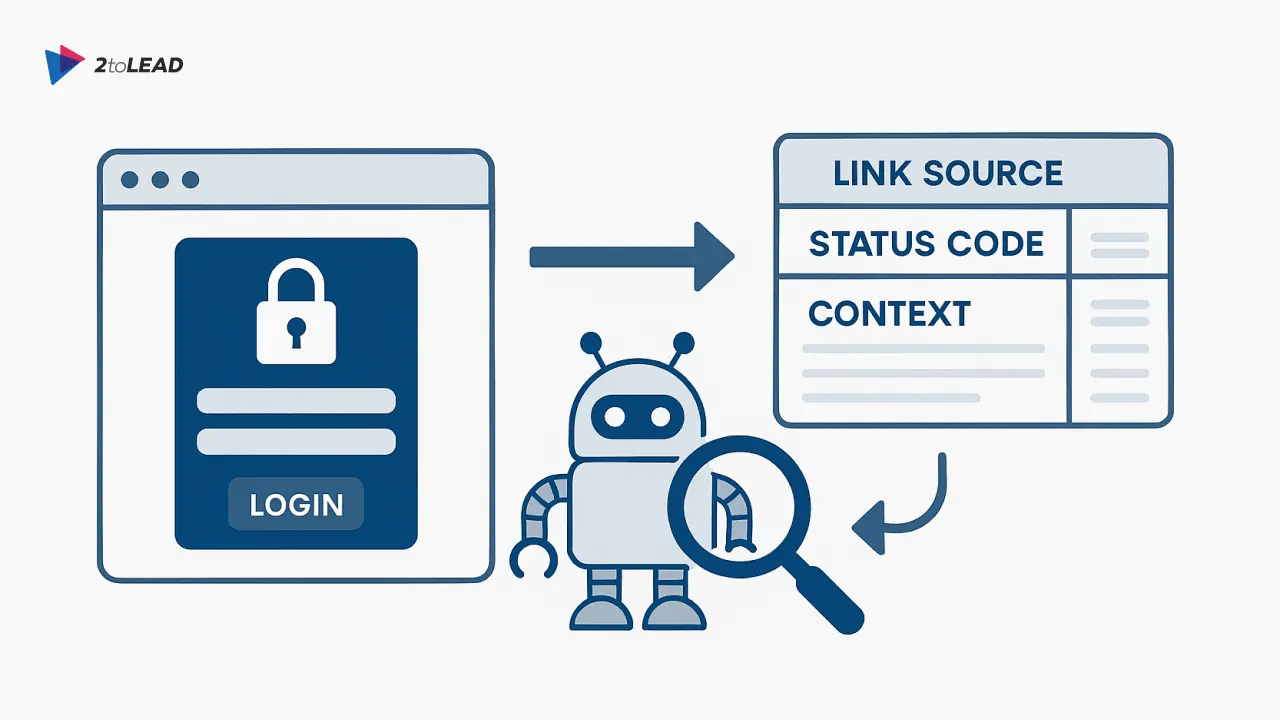
Use tools that can authenticate (SAML/OAuth) so you can detect links visible only to logged-in users. The crawler must export link source, status code, and context.
Implement redirect rules at the platform edge (CDN or reverse proxy) when possible, to keep fixes centralized and fast. Keep a CSV-driven redirect table so changes are auditable.
PowerShell scripts or Graph API scripts are indispensable for bulk updates in modern platforms: replacing document-internal links, updating metadata, and applying permission changes in bulk.
If available, use migration tools that preserve link relationships or generate a map of old-to-new object IDs during migration to speed up redirects.
Integrate broken-link detection with your observability stack so new 404/403 spikes create tickets automatically.
(Choose tools that support exportable reports. You’ll need them for auditing and reporting to stakeholders.)
Fixes aren’t done once, they must be monitored.
Schedule daily or weekly authenticated crawls for the first 30–90 days, then weekly or monthly depending on site churn. Feed crawl outputs into a dashboard and trend 4x or 5x over time.
Create synthetic user journeys for critical workflows (e.g., open the HR onboarding page → download forms → submit). Run these tests on a schedule and alert on failures.
Track help desk ticket themes. If multiple tickets reference the same link or workflow, escalate to P1 remediation.
Assign content owners and SLAs for link fixes: e.g., P1 within 24 hours, P2 within 7 days. Keep a log of fixes and who applied them for post-migration retrospectives.





Join Our Newsletter

.webp)




