

AI teams want more than access to powerful models. They want speed, flexibility, and a simple way to move from testing into production. That is why Fireworks AI on Microsoft Foundry matters. Microsoft introduced Fireworks AI on Foundry in public preview to bring high-performance, low-latency open model inference into Azure.

This launch is important because many organizations want the benefits of open models without building a complex serving stack on their own. Microsoft Foundry is positioned as a unified control plane for AI. It brings together models, agents, evaluation, deployment, and governance in one experience. Fireworks AI adds the fast inference layer that helps make open models more practical at enterprise scale.
Fireworks AI on Microsoft Foundry gives developers access to fast open model inference inside Azure. In simple terms, it helps teams run open models with better speed and lower latency while using Foundry as the place to discover models, deploy them, and operate them more consistently. Microsoft says the goal is to give developers a single place to run open models efficiently while also customizing and operationalizing them as part of an enterprise-ready AI lifecycle.
This matters because open models continue to gain attention across the enterprise. Many teams want more freedom to choose the right model for the right workload. They also want more control over performance, cost, customization, and the security and compliance needed for deployment. Microsoft says open models help teams avoid lock-in to a single model provider as needs evolve.
Microsoft Foundry makes that easier by giving teams a more consistent environment for evaluation and deployment. Rather than juggling disconnected tools, developers can work from one platform that supports model access, operational workflows, and governance.
As AI adoption grows, model access alone is no longer enough. Organizations need a reliable way to evaluate models, put them into production, monitor their use, and improve them over time. Microsoft notes that too many teams still have to assemble bespoke serving stacks, which slows innovation and makes scale harder.
That is where the Fireworks AI and Foundry combination stands out. Fireworks AI is focused on inference performance. Foundry provides the broader enterprise layer around that performance. Together, they create a smoother path from experimentation to production.
This is especially useful for organizations trying to build repeatable AI practices instead of one-off pilots. Speed matters, but so do governance, observability, and a clear operating model. A platform that supports all of that is more useful than a fast model endpoint on its own.
Microsoft describes Foundry as a single place where teams can evaluate, deploy, customize, and operate open models alongside the rest of their AI stack. That framing is important because customization today is about more than model training. Teams also need to configure, deploy, optimize, govern, and update models in production.
The model catalog experience supports that story well. It shows how developers can browse models in one place instead of moving between separate environments. This kind of centralized experience can help reduce fragmentation across AI programs. It also gives teams a better foundation for comparing model choices and aligning deployment decisions with governance needs.
Microsoft says developers can access several open models through Fireworks AI on Foundry today, including DeepSeek V3.2, OpenAI gpt-oss-120b, Kimi K2.5, and MiniMax M2.5. That gives teams more room to choose a model based on workload needs rather than forcing every scenario into the same architecture.
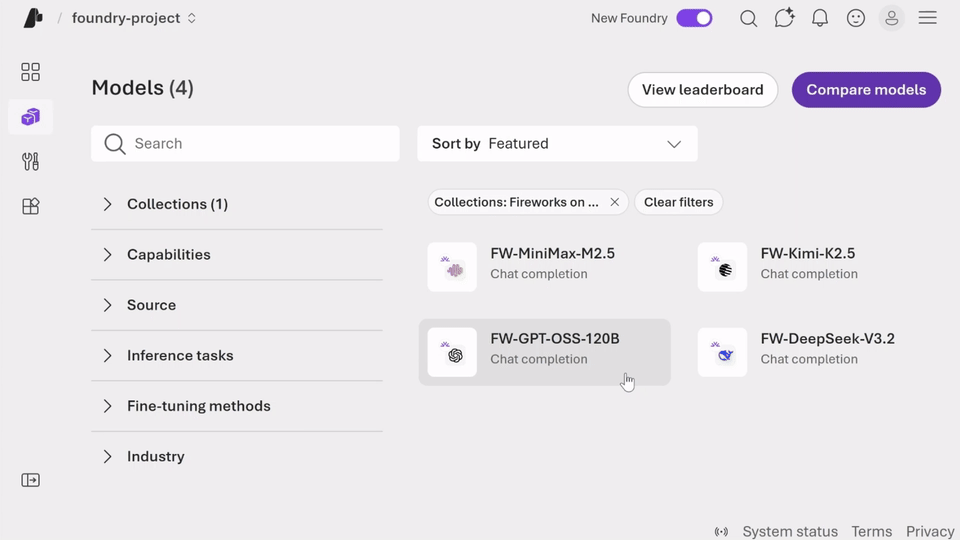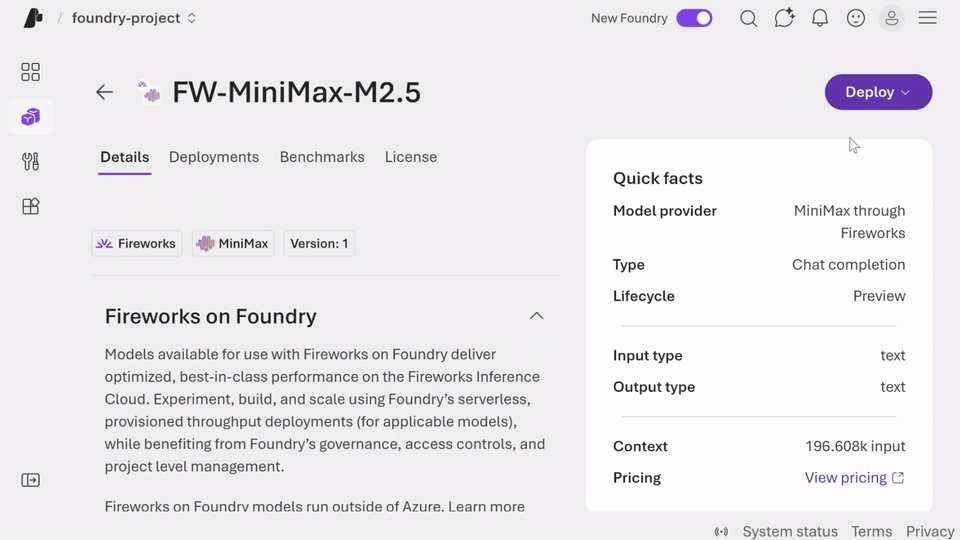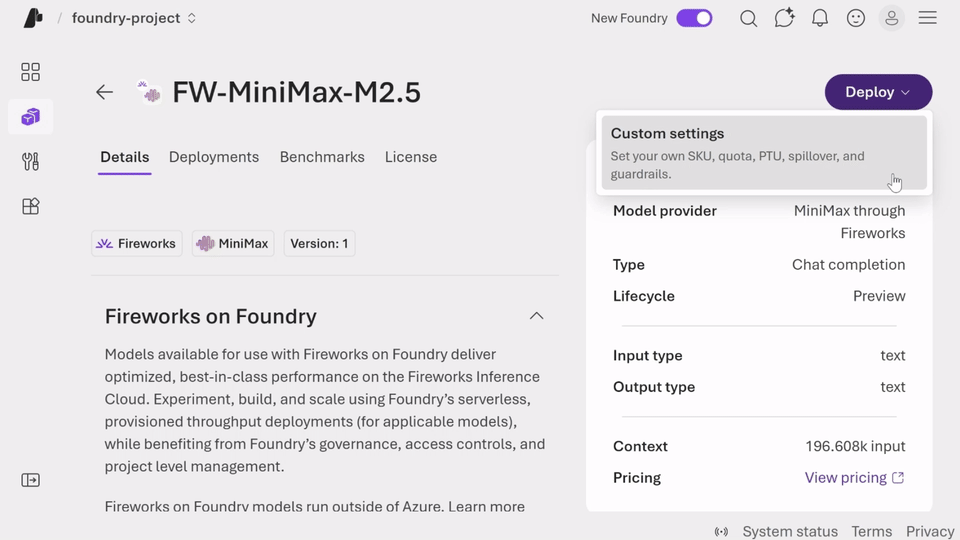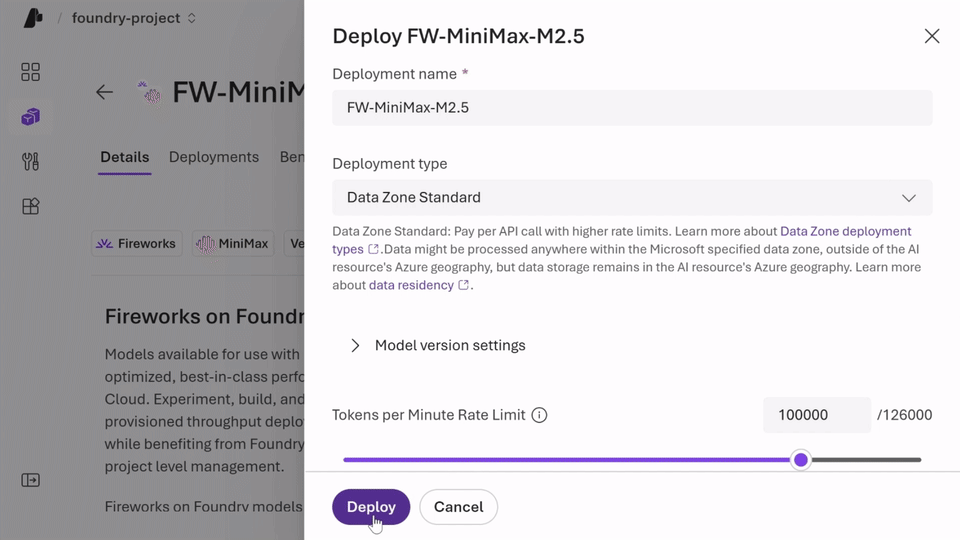
Microsoft highlights several practical benefits of Fireworks AI on Foundry. One of the biggest is faster evaluation. Teams get access to leading open models through a single Azure endpoint, which reduces setup friction and helps developers start experimenting sooner.
Another major benefit is optimized inference. Requests to open models are served through Fireworks AI’s high-throughput inference stack. For enterprise teams, that matters because performance problems can quickly limit the usefulness of an otherwise strong model strategy. Lower latency helps improve user experience and supports more demanding real-time applications.
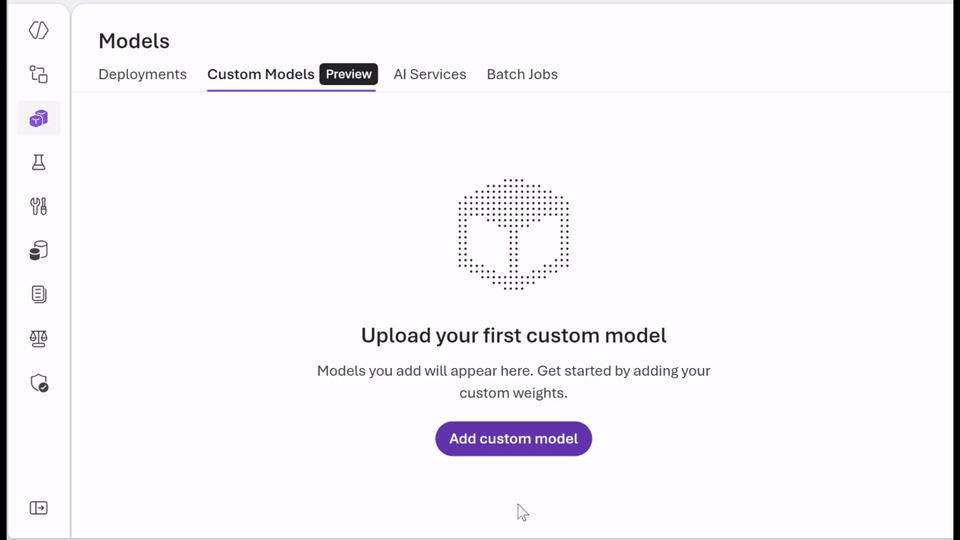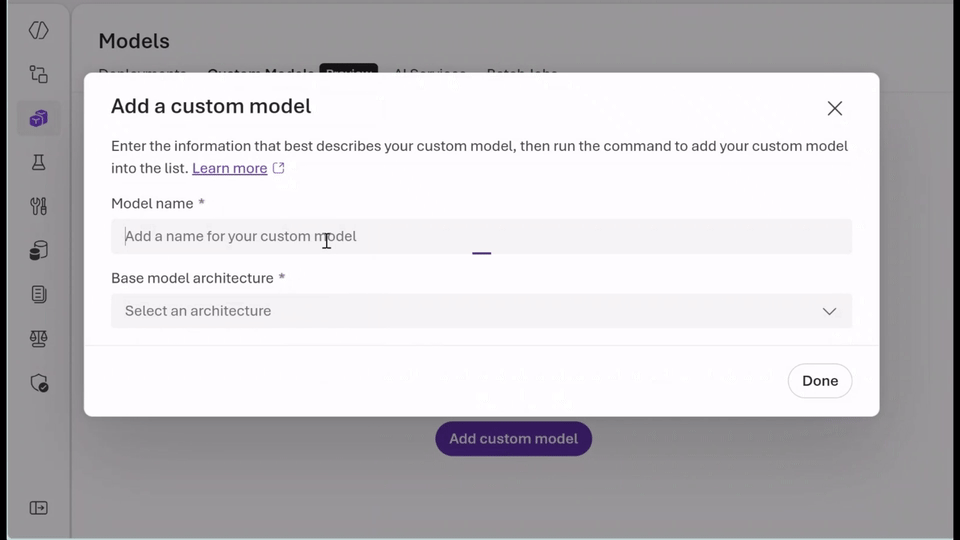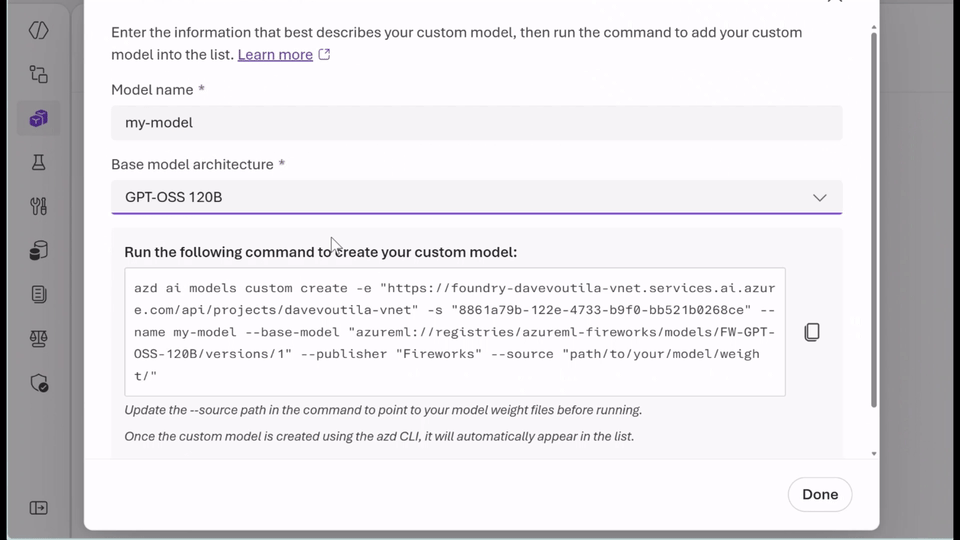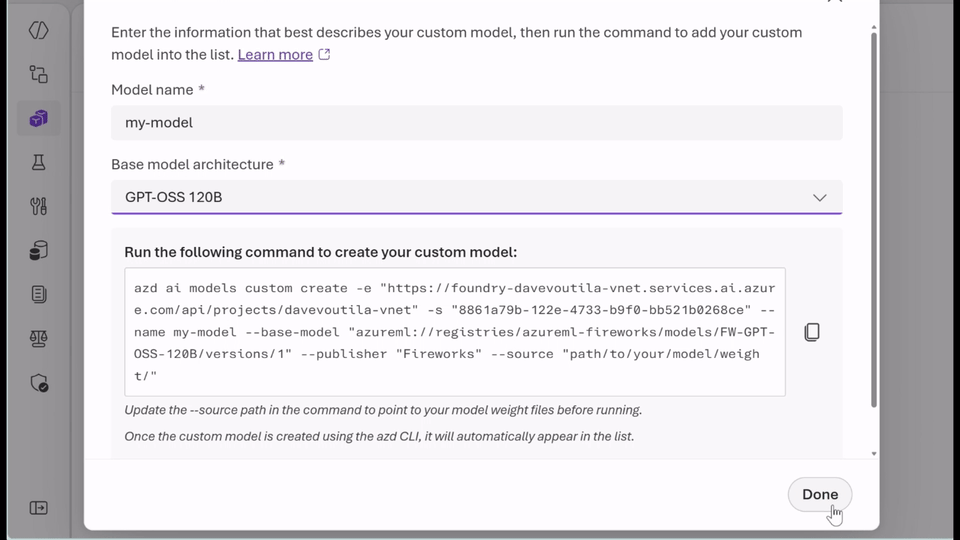
A third advantage is bring-your-own-weights support. Microsoft says organizations can upload and register quantized or fine-tuned model weights trained elsewhere without changing the serving stack. That is useful for teams that already have custom work underway and do not want to rebuild around a different inference path.
The deployment model is also part of the value. Microsoft says customers can use serverless, pay-per-token inference to experiment quickly and securely, or choose provisioned throughput units for more predictable steady-state performance.

This is important because AI workloads are not all the same. Some teams are still testing use cases and need a flexible starting point. Others are planning for production traffic and need stronger predictability around throughput and performance. Giving both options inside the same environment can help organizations scale more confidently.
This part of the story also reinforces why Foundry matters beyond the model itself. The platform is not only about access. It is about giving teams a better operating foundation for how they deploy and manage AI over time.
The bigger takeaway is not only about faster inference. It is about operational maturity. Microsoft Foundry is evolving to support the full lifecycle of open models, from early evaluation to production operation and ongoing optimization. That suggests Microsoft is building Foundry to be more than a model catalog.
For business and IT leaders, that matters because open model adoption can become complex very quickly. Teams want flexibility and strong performance, but they also need governance, observability, and security. Fireworks AI on Microsoft Foundry aims to bring those needs together in one place.
That balance is what will likely matter most to enterprises. Open models are becoming more capable, but organizations still need a trusted way to scale them. A platform that combines model choice, faster inference, deployment flexibility, and enterprise controls is easier to build on over time.
Fireworks AI on Microsoft Foundry gives Azure customers a stronger way to run open models in production. It combines low-latency inference with a centralized Azure environment for deployment, customization, and governance. For organizations exploring open models, that can reduce complexity and make it easier to scale AI with more confidence.
As enterprise AI adoption continues to grow, platforms that support both performance and operational control will matter more. This launch shows Microsoft pushing Foundry further in that direction.
I can also give you the same blog in your usual 2toLead format with a CTA, internal link placements, and a meta title.





Join Our Newsletter







