
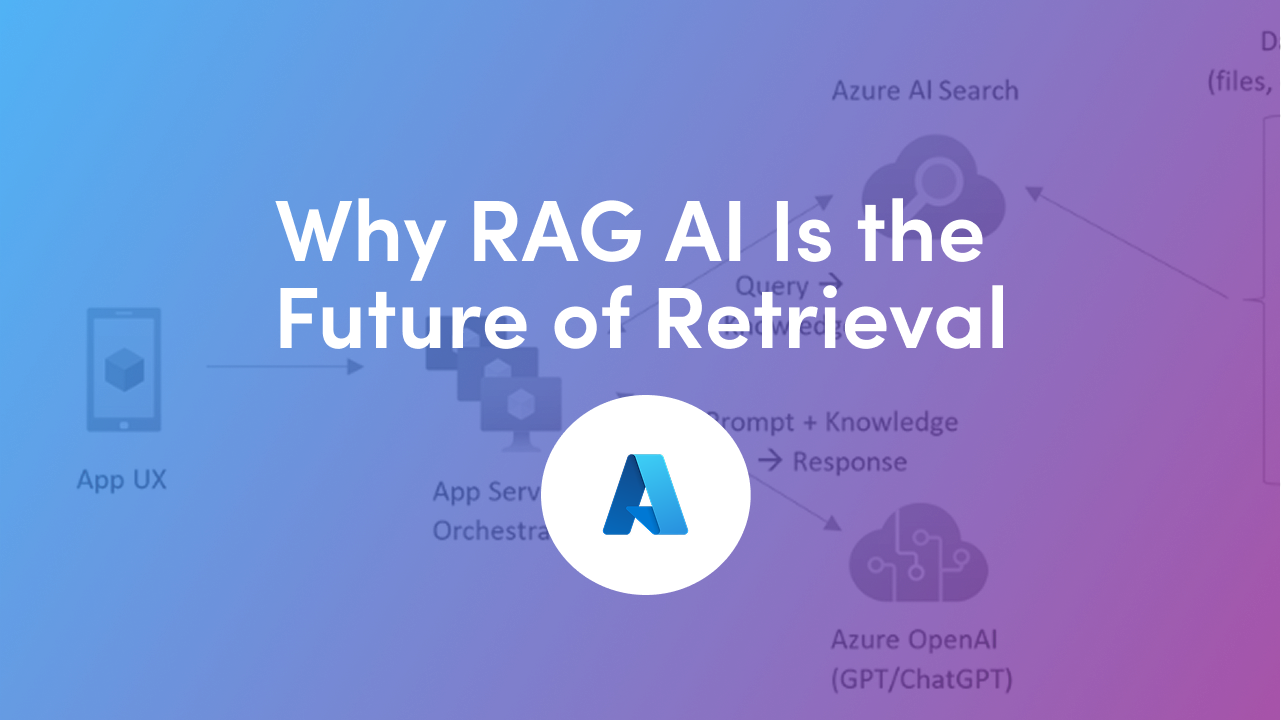
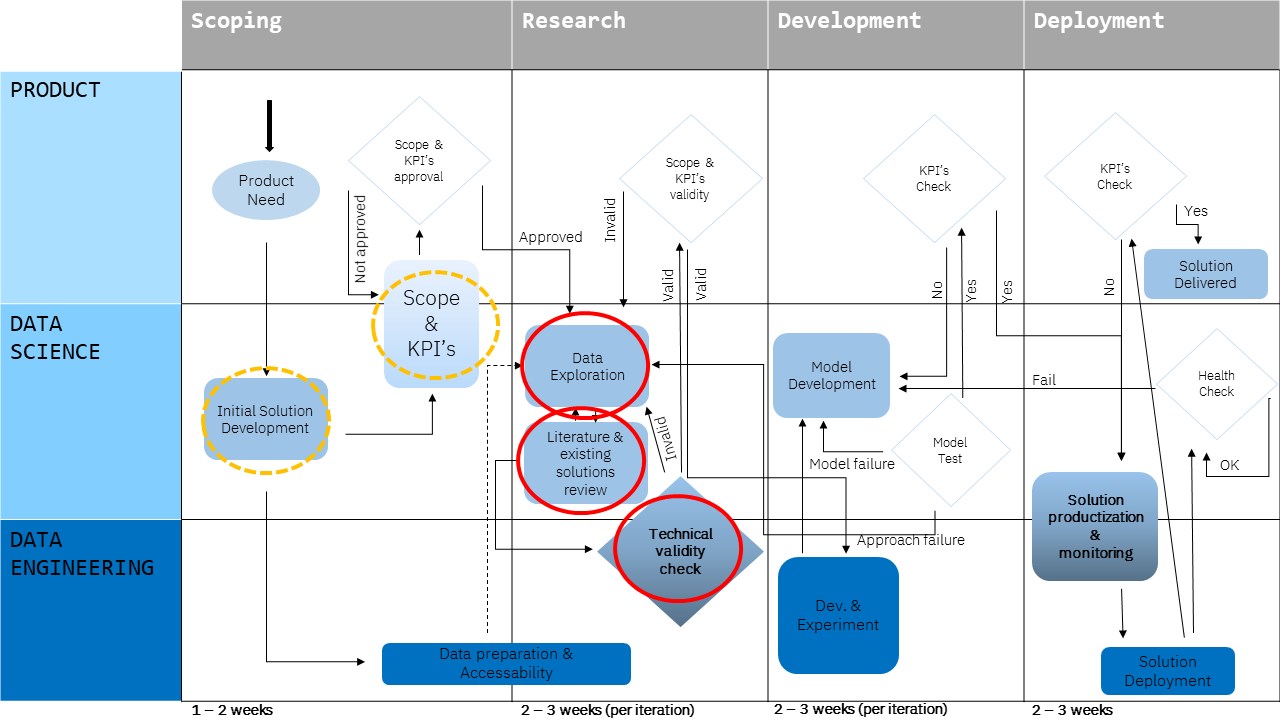
Retrieval-Augmented Generation (RAG) is one of the most exciting developments in the world of AI. At its core, RAG combines the power of large language models (LLMs) with external knowledge sources so AI can generate more accurate, relevant, and useful responses. Instead of relying only on what the model has memorized, RAG grounds answers in real data.
That makes it perfect for applications like chatbots, knowledge assistants, and domain-specific tools. But while building a prototype RAG system is straightforward, putting it into production is a very different challenge. Issues like scalability, cost, freshness of data, and reliability quickly come into play.
This blog breaks down practical steps to take your RAG system from “just working” to truly production-ready with a focus on efficient indexing, low-latency retrieval, and vector database best practices. We’ll also look at how Azure AI and recent research are shaping the future of RAG systems.
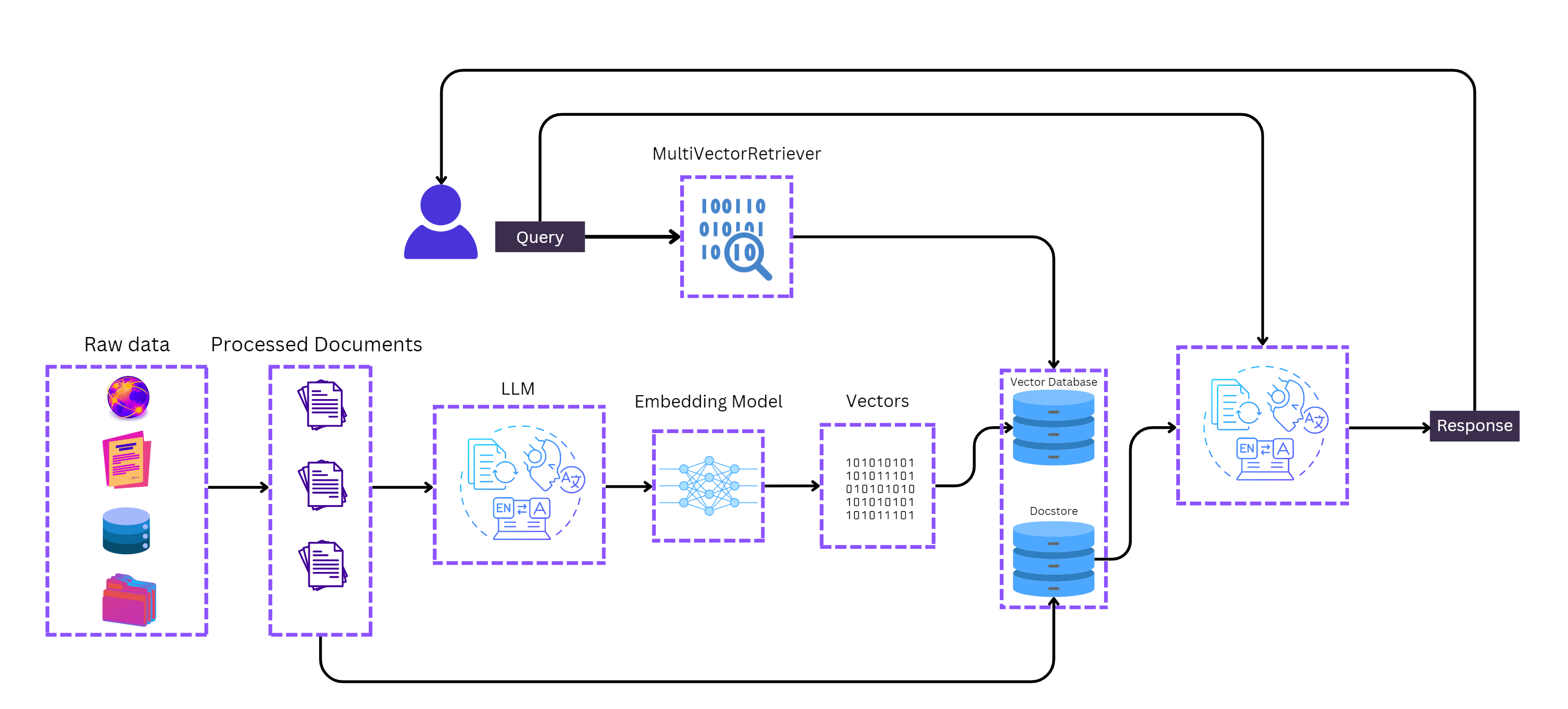
A RAG pipeline starts with indexing the process of preparing your content so it can be retrieved effectively later. Think of indexing as organizing a library so that the right book can always be found quickly.
Here’s how to approach it:
When done right, efficient indexing ensures your RAG system can scale and stay responsive. Tools like LangChain’s WebBaseLoader for ingestion, RecursiveCharacterTextSplitter for chunking, and Chroma or Azure AI vector databases are excellent starting points.
Once your data is indexed, retrieval is the next step. A high-accuracy retriever makes sure your AI system pulls the most relevant context before generating an answer.
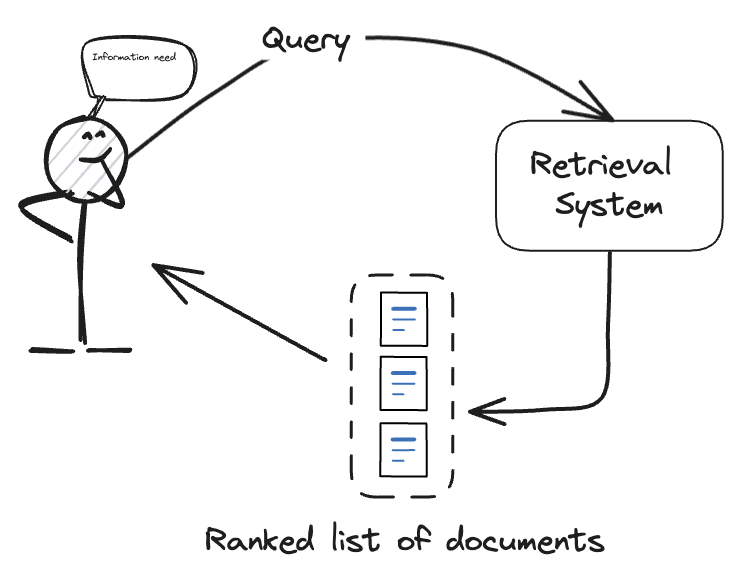
In production, you need to balance two priorities:
Vector similarity search is the most common retrieval approach, but in practice, you’ll want to apply vector database best practices to minimize lag and maximize accuracy. For example, pre-building indexes and caching frequent queries can reduce response times dramatically.
Using frameworks like LangChain makes it easy to set up a retriever. But when moving to production, make sure your retriever is optimized for low-latency retrieval so your users never feel delayed.
Retrieval is only half the story. Once the right chunks are found, they need to be passed to the LLM in a way that improves answers.
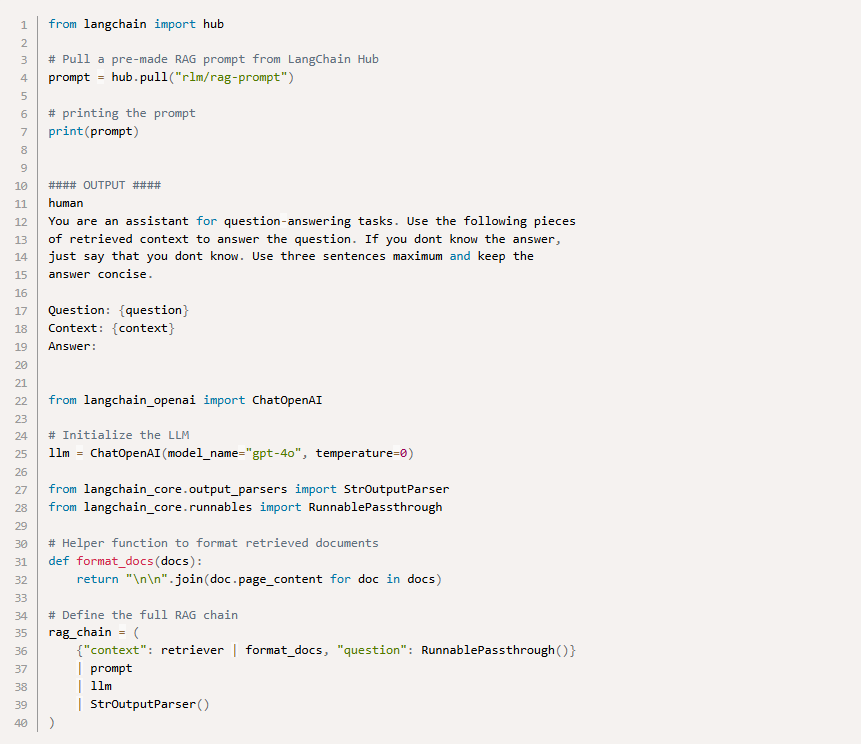
That’s where prompting comes in:
Frameworks like LangChain’s prompt hub make this easier. Good prompting, combined with retrieval, allows models like GPT-4 or Azure OpenAI models to deliver grounded, context-rich results.
A prototype RAG might work perfectly in a lab setting. But when users start interacting with it at scale, things change.
Here’s what you’ll need to manage:
This is where Azure AI tools shine. They’re designed for cloud-scale performance and can help with scaling vector databases, monitoring latency, and keeping costs under control.

Sometimes vector search alone isn’t enough. That’s where advanced strategies come in:
These methods make your retriever smarter and more adaptive, helping your RAG deliver both broad coverage and pinpoint accuracy. Microsoft’s Azure AI Search offers built-in support for many of these features.

The RAG landscape is evolving fast. Recent research offers exciting breakthroughs:
These innovations show how quickly RAG is maturing and why production systems need to keep evolving.
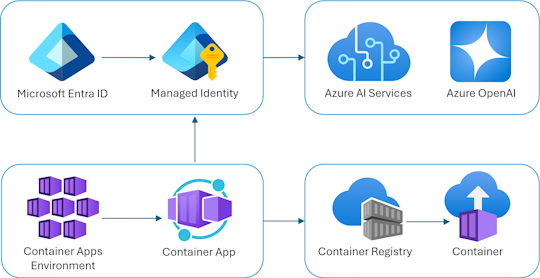
Tomorrow’s RAG systems won’t just handle text. With Azure AI Content Understanding, you can build systems that retrieve information from documents, images, audio, and even video.
Another exciting development is synthetic data. Tools like RAGSynth can generate new examples to train and test retrievers. This strengthens robustness, especially in industries with complex or scarce datasets.
By embracing multimodal capabilities and synthetic data, you can future-proof your RAG pipeline.
RAG isn’t just a buzzword it’s a game-changing approach that blends knowledge retrieval with powerful LLMs. But to make it work in the real world, you need more than a prototype.
Focus on efficient indexing, chunking strategy, and vector database best practices for strong foundations. Make sure your high-accuracy retriever is also optimized for low-latency retrieval so users get quick, reliable answers. And don’t forget about scaling, cost, and reliability, this is where platforms like Azure AI can make a real difference.
By layering in advanced retrieval strategies and tapping into cutting-edge research, your system can move from experimental to enterprise-ready. And with multimodal content and synthetic data, your RAG pipeline will be ready for the future.
Whether you’re building a chatbot, a knowledge assistant, or an industry-specific AI tool, following these steps will help you transform your RAG from zero to hero.





Join Our Newsletter






